Writing in the Margins: Proposed solution to Lost in the Middle
A practical walkthrough of the Writer team’s WiM pattern for long-context inference: chunked prefill, margin notes, and KV cache hygiene.
🏹 We will be dissecting the paper
Writing in the Margins: Better Inference Pattern for Long Context Retrieval
Imagine you’re reading a dense, complex novel. As the pages turn, the plot thickens, and crucial details are scattered across the text, each paragraph holding a piece of the puzzle. But here’s the catch: when you try to recall those key points later, they’ve become a tangled mess, lost somewhere in the middle of the story. Frustrating, right?
Now, consider this same challenge, but instead of you, it’s a large language model (LLM) tasked with understanding and synthesizing those details. LLMs, like GPT-4, are incredibly powerful, but they face their own struggles when it comes to processing long texts. They can easily get "lost in the middle," missing out on crucial information that’s buried deep into long pieces of text.
This is where the Writing in the Margins (WiM) approach comes into play, an interesting technique designed to help this very problem. All credit to the Writer team.
In this blog, we will deep dive into what WiM is, how it works, and why should we care.
The Problem: Lost in the Middle
LLMs are typically designed to process text up to a certain length, known as the context window. When the text exceeds this length, the model either truncates the input (potentially missing crucial information) or struggles to maintain coherence and relevance across the entire context. This issue becomes even more pronounced when dealing with texts where relevant details are not just at the beginning or end but scattered throughout, a scenario often referred to as the "lost in the middle" problem.
The Solution: Writing in the Margins (WiM)
The Writing in the Margins (WiM) approach provides a novel solution to the "lost in the middle" problem.
But what the heck is "Margin"?
Just like we jot down notes in the margins of a book highlighting the important stuff without having to reread the whole thing, WiM enables language models to do the same by breaking down long context into smaller chunks/segments, and for each chunk, WiM extracts its own "margin" (aka intermediate summary). These margins capture the most important points of each segment, focusing on the information most relevant to the task at hand.
Since it’s inspired by the margins of the book, therefore the term “Margin”.
Key Features of WiM
- Chunking the Long Context: WiM breaks down long texts into smaller chunks.
- Processing Each Chunk Individually: Generating margin notes (summaries) and classifying these margin notes to determine their relevance to the query.
- Integrating Margins into Final Inference: Using these combined notes along with the original instruction to generate a precise and informed final response.
- Memory Efficiency: The method is designed to be computationally efficient, leveraging a partially prefilled KV cache to avoid multiple reprocessing steps.
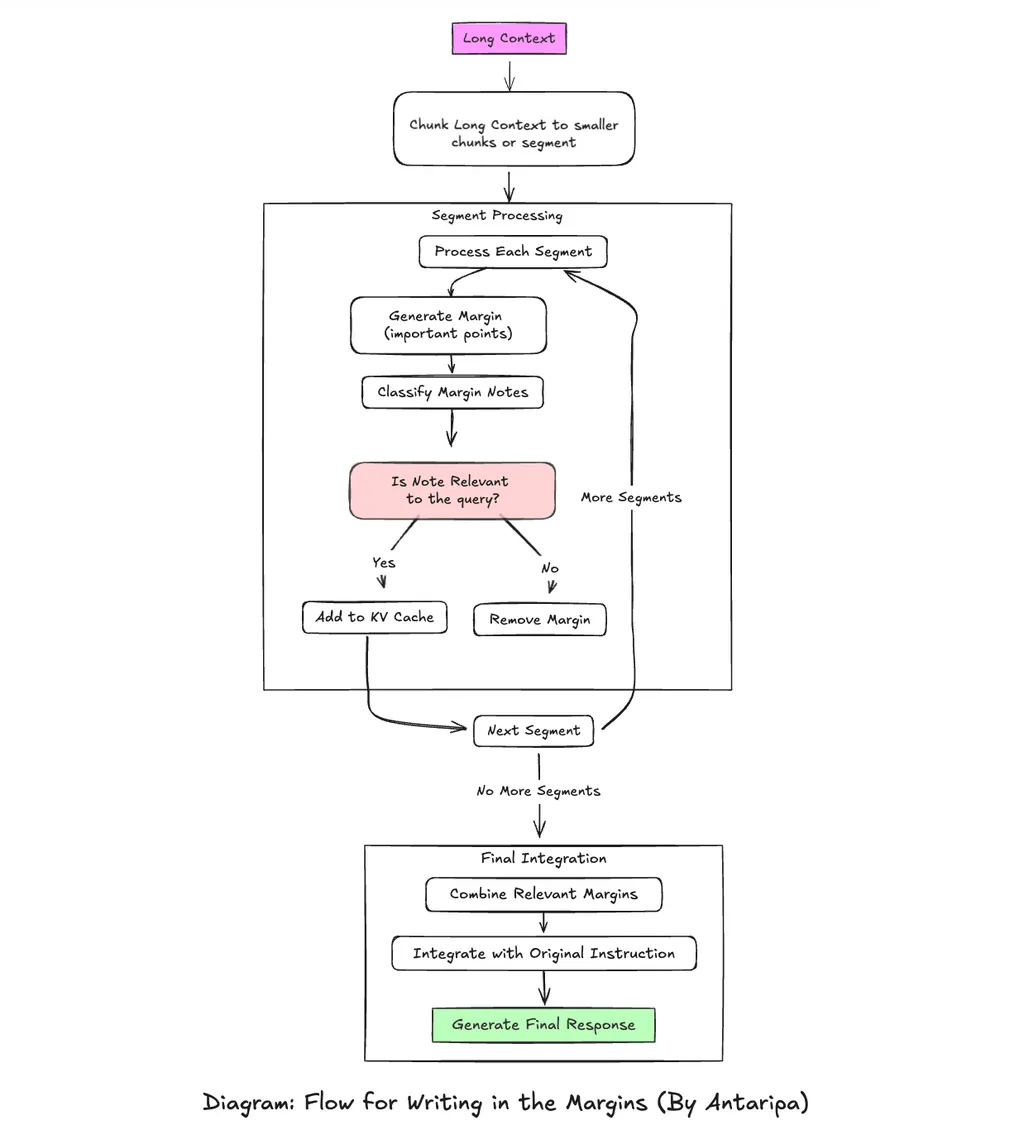
How WiM Works: Step-by-Step Breakdown
Step 1: Chunking the Text
The first step in WiM is to divide the long input text into smaller segments or chunks. We need to decide an optimal size (say 1000 tokens) for the chunks, considering the model’s context window limit and the nature of the task. The chunks are divided ensuring that the splitting respects natural boundaries where possible (e.g., paragraph or section breaks) to maintain coherence within segments.
Splitting long context into N segments:
Step 2: Prefilling the KV Cache (Chunked Prefill)
If you don’t understand the concept of Chunked Prefill properly, I suggest understanding this concept first → Chunked Prefill
Next, the model prefills the KV cache with the initial context. Before processing any chunks, the KV cache is set to empty. The KV cache is a critical component in transformer models like GPT-4, storing intermediate representations (key-value pairs) that the model uses to maintain context across multiple steps. In WiM, the system message (which sets the overall context for the task) is prefilled into the KV cache. This serves as the foundation upon which subsequent chunks are processed.
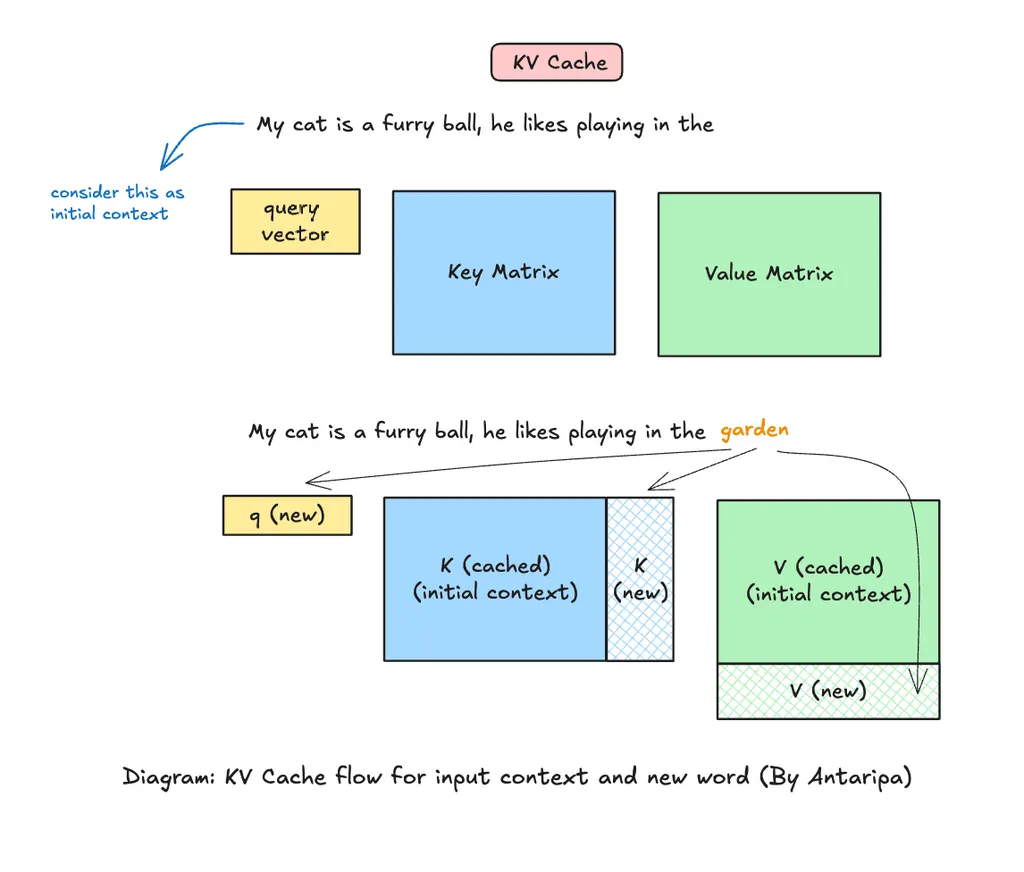
What is KV cache, how, and why does this work? [general explanation of KV cache]
A KV cache is a data structure that stores the keys and values from previous tokens so they can be reused for subsequent tokens, preventing the need to recompute these keys and values for already processed tokens. This speeds up the generation process because the model can simply look up cached values rather than recalculating them from scratch.
As shown in the diagram:
- Initial Context: For the initial context (e.g., "My cat is a furry ball..."), the model generates the keys, values, and queries for all the tokens. Once generated, the keys and values are cached. This prevents the model from having to regenerate them when processing future tokens (avoiding unnecessary repetitive computation)
- New Token Generation: When a new word like "garden" is generated, the model creates a key, value, and query for this token. The model then uses the cached keys and values from the initial context along with the new token's query to calculate attention. This allows the new token to efficiently attend to both the cached context and itself.
- Cache Update: The key and value for the newly generated token are added to the cache, allowing for further efficient computations in future steps.
Why It Works:
The reason KV caching improves efficiency lies in the self-attention mechanism. In a transformer, each token attends to every other token in the sequence. Without caching, every new token would require recalculating keys and values for all preceding tokens, leading to an exponential growth in computation as the sequence length increases.
Step 3: Processing Each Chunk
With the KV cache prefilled, the model begins processing each chunk sequentially:
- Segment Processing: As each chunk is processed, it updates the KV cache with new key-value pairs. When the next chunk is processed, it builds upon the context established by the previous chunks, leveraging the already populated KV cache.
- Extractive Summary Generation: For each chunk, the model generates a margin (short intermediate summary) that highlights the most important information relevant to the query.
Step 4: Classifying the Margins
Once a margin is generated, it’s important to determine whether it’s relevant to the overall query. WiM introduces a classification step where the margin is evaluated:
- Classification: The margin is passed through a classification model, which assesses its relevance. If the margin is considered relevant, it is kept; otherwise, it is discarded.
- Cache Management: After classification, the KV cache is adjusted by removing the tokens related to the extractive summary and margin generation. This ensures that only relevant information is retained in the cache, optimizing memory usage.
Deleting from the End of the KV Cache:
The author mentions that we can delete something from the end of the KV cache without affecting the prior context. This is possible because the KV cache at the end only stores information about the most recent tokens. Removing these doesn't disrupt the embeddings or relationships of earlier tokens.
Step 5: Final Answer Generation
After processing all the chunks, the relevant margins are concatenated into a single logical and relevant summary. This summary serves as the foundation for generating the final answer:
- Prefill Final Answer Prompt: The concatenated margins are prefilled into the model along with a final prompt, which asks the model to generate a comprehensive answer based on the gathered information.
- Generate Final Answer: The model uses the context provided by the margins to produce a final, well-informed response to the query.
Technical Insights
The WiM approach is built on a solid foundation of transformer-based models and leverages advanced techniques like chunked prefill, KV cache management, and top-p sampling.
To generate text, WiM uses top-p sampling, a technique that selects tokens based on their cumulative probability. This method ensures that the model generates diverse and coherent text, avoiding the pitfalls of deterministic approaches like always picking the most probable token.
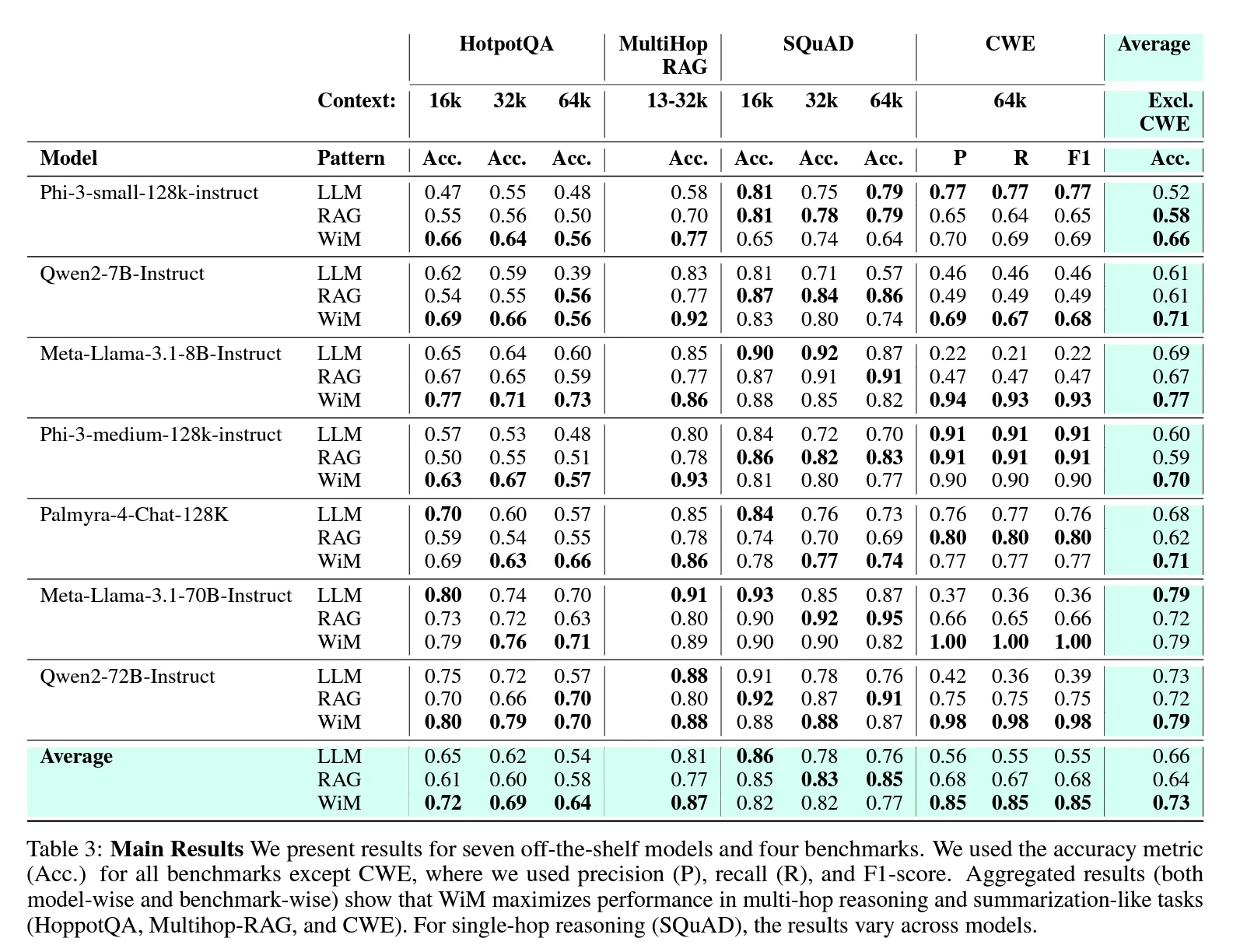
To evaluate the effectiveness of the Writing in the Margins (WiM) pattern, it has been compared with long-context LLMs and RAG-based techniques to generate answer for a given query from a very long context:
- Long Context LLM (LLM): The entire context is fed into the language model without chunking.
- Retrieval Augmented Generation (RAG): A few chunks of the context are selected based on a retriever (e.g., using cosine similarity between query and segment/chunk vectors) and then concatenated with task instructions before being fed into the language model.
To make the comparison fair, the retriever in RAG was replaced with the classifier used in WiM.
Result of the experimentation (taken from the paper):
Conclusion
The Writing in the Margins approach is a powerful tool for anyone working with large language models and long texts. It smartly addresses the "lost in the middle" problem.
As we continue to push the boundaries of what language models can do, approaches like WiM will be essential in making these powerful tools more effective, accessible, and user-friendly.
References
(The Writer Team was inspired by vllm’s implementation of chunked prefill)